
隨著ChatGPT、Genesis和Claude等大型語言模型的崛起,全球數據生成量呈現爆發式增長。IDC預測,到2028年全球創建、獲取、復制和消費的數據總量將達到394ZB。
當前,大模型領域的競爭已全面展開——從硬件架構到軟件算法的各個層面,廠商都在展示技術實力。而擁有海量數據存儲經驗的云服務商們,正通過優化硬盤與固態硬盤的混合存儲架構,為規模化AI分析提供支撐,并推出一系列創新AI應用。
一、AI如何重塑數據存儲及其演進需求
隨著數據的爆炸式增長,生成式人工智能應用日益普及。更加豐富的內容形態、更多次的數據復制和轉換、更長的數據保留時間以及數據監管和數據管理要求的升級,共同催生了更龐大的數據創建和存儲需求。
數據已成為AI成功的核心要素,其在希捷提出的“AI數據無限循環”中流經六大節點:源數據、訓練模型、創建內容、存儲內容、保存數據和重復利用數據。每個階段都需要差異化的存儲方案組合:
AI模型的訓練、后處理及微調過程天然需要消耗大量數據和存儲資源,尤其是各行業特有的非公開數據集,這些數據對開發具有領域針對性的AI系統至關重要。雖然并非所有AI應用都需要“無限”的數據支撐,但現代深度推理系統的有效性很大程度上依賴于大規模高質量數據集——隨著AI技術向新領域拓展,這種依賴性愈發顯著。當前的一個關鍵趨勢是:在推理能力進步和成本優化部署的雙重推動下,以往未被充分利用的數據源(如醫療領域的患者病歷、能源勘探中的地震數據等行業記錄和現實場景數據)正被整合到AI工作流程中。這一轉變使得曾被邊緣化的數據類別融入AI核心應用范疇,進一步促進市場擴張。
鑒于AI在現代數據生態中的無處不在,“通用數據”與“AI專用數據”正在融合為單一類別——這場變革將以指數級速度加速全球數據領域的擴張。
二、數據存儲在AI工作流中的關鍵作用
AI工作流是由多個復雜環節組成的完整過程,每個階段都需要專門的存儲解決方案支撐。從數據預處理、模型訓練、推理部署到長期歸檔,不同環節對存儲性能、容量和成本效益各有側重。隨著AI系統的持續演進,存儲技術必須同步創新,在確保可擴展性、效率與可靠性的同時,滿足這些動態變化的需求。
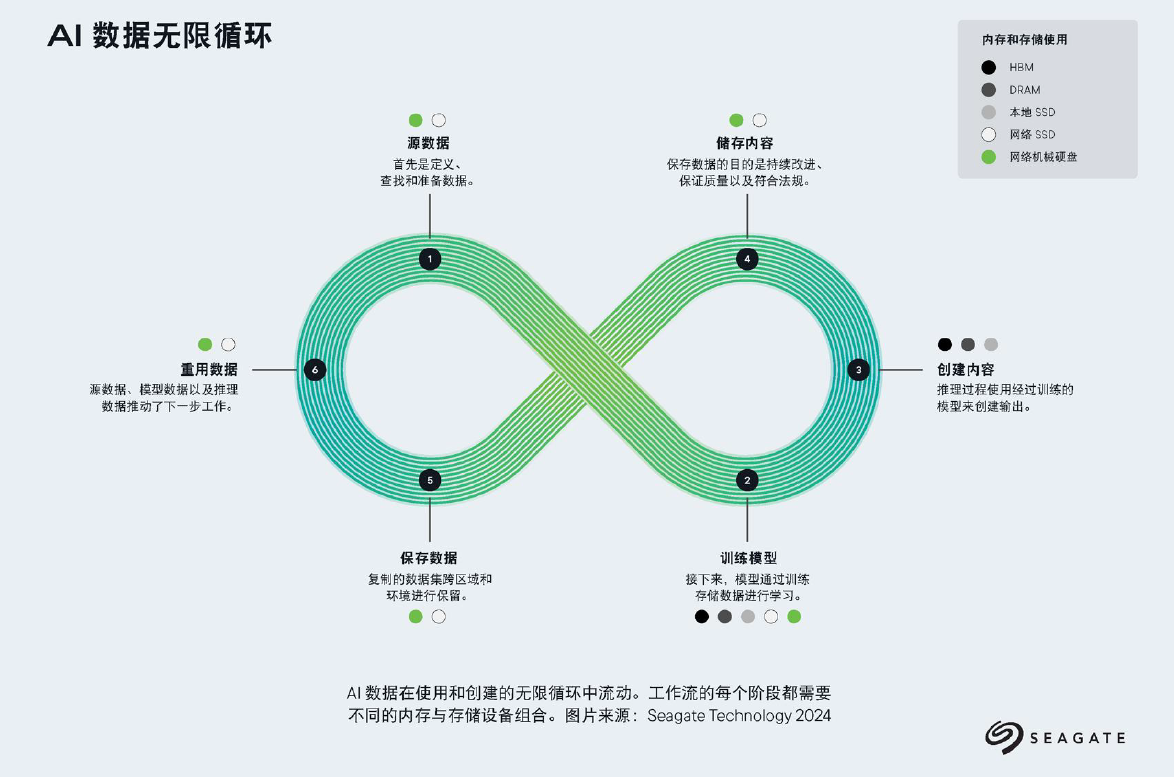
1、源數據:AI成功的基石
人工智能模型的有效性取決于能否訪問來自不同來源的海量高質量數據集,因此存儲架構必須能夠超越“SSD=快/HDD=慢”這種簡單的二分法。如今的高密度機械硬盤已發展成為大規模AI工作流的高效組件,它們不僅作為冷存儲層存在,更是分布式緩存系統的活躍參與者。憑借無可匹敵的容量成本比,HDD實現了EB級甚至更大規模數據操作的可持續擴展。
當前,行業領導者已在需要超高吞吐量和持久數據可用性的地理分布式AI/ML部署中采用HDD,充分證明其與SSD共同構成了現代存儲體系的核心支柱。這些架構實踐表明,經過創新的HDD技術已從昔日的“傳統”存儲介質,蛻變為可擴展AI基礎設施的關鍵基石。
2、模型訓練:存儲需求的核心戰場
訓練諸如ChatGPT或GROK等大型語言模型(LLM)需要反復訪問PB級數據,這對存儲系統提出了雙重挑戰——既要滿足梯度計算所需的高速訪問,又要保障數據集持久化存儲的大容量需求。在這一計算密集型階段,高性能存儲架構通常采用HBM、DRAM 和本地SSD進行學習。
檢查點具體發生在模型訓練階段。它通過定期保存包含模型數據、參數和配置設置的完整快照,為訓練過程提供多重保障。這些檢查點不僅可以作為防止意外中斷的保障措施,避免訓練進度丟失,還能完整記錄模型參數的演化軌跡,為開發者提供寶貴的記錄依據。為確保檢查點的安全存儲與高效訪問,業界普遍采用網絡硬盤和SSD存儲檢查點以保護和改進模型訓練。
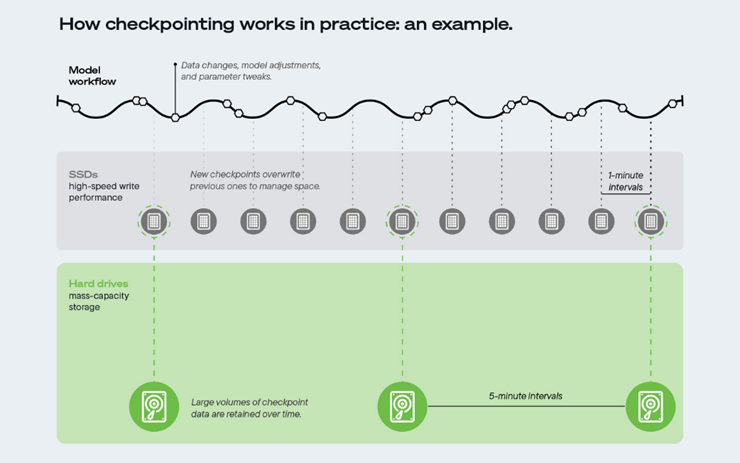
模型訓練期間的數據保留呈現出明顯的階段性特征。如圖所示,模型工作流程會持續生成數據變更和參數調整,高速SSD會頻繁執行快速檢查點寫入,同時覆蓋先前的數據以滿足實時性要求。這種高頻覆蓋機制可確保高效的訓練進程,這意味著活躍的訓練數據通常僅保留幾分鐘。相比之下,大容量HDD則承擔著長期存儲的職責,將海量檢查點數據集保存數周甚至數月,從而維護全面的歷史檔案。
3、推理與內容生成:速度與經濟性的兼顧
在推理階段,AI系統需實時響應各類查詢請求(如聊天機器人、推薦引擎等),這就要求存儲系統在實現微秒級數據訪問的同時保持成本可控。支撐這一持續創作過程的核心存儲技術包括:HBM、DRAM和本地SSD。
4&5、內容存儲與留存:耐用性與合規性并重
AI生成內容(如合成媒體、學術論文及大規模數據集)在產出后,需要滿足三大核心要求的長期存儲方案:超大容量、能源高效與合規留存。隨著各行業AI生成內容的爆發式增長,可擴展存儲基礎設施的需求呈指數級上升。這類技術不僅能顯著降低運營成本,還可有效減少碳足跡,與全球可持續發展目標高度契合。
此外,要確保數據長期完整性,必須采用先進糾錯協議并實施定期完整性校驗,從而有效防止數據劣化或過時問題。合規性要求更進一步增加了存儲策略的復雜性——不同司法管轄區對數據留存期限、可訪問性及隱私保護的規定往往存在差異。通過將可擴展的節能存儲方案與完善的合規框架相結合,企業既能使其AI產出具備前瞻適應性,又能滿足持續演進的監管要求與環保標準。
像英國國家檔案館這樣需要長期保存PB級數據(20年合規留存)的大規模AI項目,必須采用能夠兼顧性能與容量的存儲架構。總部位于美國的Iron Mountain公司協助英國國家檔案館部署了AI及機器學習系統,該方案能自動識別符合永久保存要求的檔案,從而滿足留存20年的規定。該系統可以完成記錄篩選、重復項檢測、實體提取及文件評估等全流程處理,最終確定歸檔內容。
6、數據再利用:源數據、模型數據和推理數據將助力下一步工作
內容輸出反饋到模型中,從而提高其準確性并賦能新模型。網絡硬盤和固態硬盤為跨地域的AI數據協同生產提供支撐,使原始數據集與處理結果能持續轉化為新工作流的輸入源。
AI技術的下一前沿不僅關乎算法優化,更在于重構數據存儲、訪問與再利用的全流程范式。展望未來,數據中心運營商需重點考量三大戰略方向:重新評估數據留存策略以保留曾被丟棄但具潛在價值的數據集;推動基礎設施從集中式向分布式-解耦架構演進;優化功耗、服務等級協議(SLA)與可擴展性的三角平衡。這些決策將直接決定AI系統如何有效地充分利用其數據潛力。
三、激烈的競爭與永無止境的創新之旅
作為全球領先的EB級存儲解決方案供應商,希捷一直走在滿足日益增長的數據存儲需求的前沿。
希捷最新推出的魔彩盒3+(Mozaic 3+)平臺彰顯了公司對創新的執著追求,為可擴展的AI解決方案提供了清晰路徑。這一尖端技術平臺助力客戶能夠高效擴展其存儲基礎架構,優化總體擁有成本,并實現可持續發展目標。在AI驅動的數據中心,高存儲容量至關重要,不同的存儲介質在性能和可擴展性方面具有不同的優勢。希捷的熱輔助磁記錄(HAMR)技術顯著提升了面密度,提升了硬盤的容量、性能和能效,并將實現單碟片10TB的突破性容量。
希捷率先將NVMe技術引入大容量硬盤領域,推出革命性解決方案,該技術已通過試點項目得到驗證。通過將NVMe發展為未來硬盤連接標準協議,希捷提供了一種創新選擇,既能優化AI數據流水線、減少存儲瓶頸,又可保留硬盤在成本與存儲密度方面的傳統優勢。與傳統基于SAS/SATA的硬盤相比,NVMe硬盤無需主機總線適配器(HBA)、協議橋接器和額外SAS基礎設施,從而顯著簡化了AI存儲架構。尤為關鍵的是,該技術還支持GPU直接訪問。通過在高密度硬盤存儲與高速SSD緩存之間構建統一的NVMe架構,從而實現AI工作負載的無縫擴展。
希捷正積極攜手客戶及AI生態領軍企業,共同驗證該技術在AI全價值鏈中的實際效能。此類深度合作將助力構建標準參考架構,從而確立NVMe硬盤在AI基礎設施中的長期戰略價值。
四、總結
希捷對技術創新的不懈追求,彰顯了其在應對現代數據中心不斷演進需求中的關鍵作用。通過持續提升存儲容量并推動全行業協作,希捷不僅可以滿足當前需求,更為人工智能等領域的未來發展奠定了基礎。
隨著競爭格局的加劇,企業將傾向于采用能夠利用尖端硬件技術并優化配置的架構。在應用性能和投資效率之間取得適當的平衡,對于在這種動態環境中蓬勃發展至關重要。通過實現這種平衡,企業不僅可以跟上技術進步的步伐,還可以推動人工智能和數據存儲領域的未來創新。
文/作者:Jason Feist,希捷科技云業務營銷高級副總裁
免責聲明:以上內容為本網站轉自其它媒體,相關信息僅為傳遞更多信息之目的,不代表本網觀點,亦不代表本網站贊同其觀點或證實其內容的真實性。
Copyright 1997-2022?電腦報官網?All Rights Reserved














 渝公網安備 50010302003670號
渝公網安備 50010302003670號