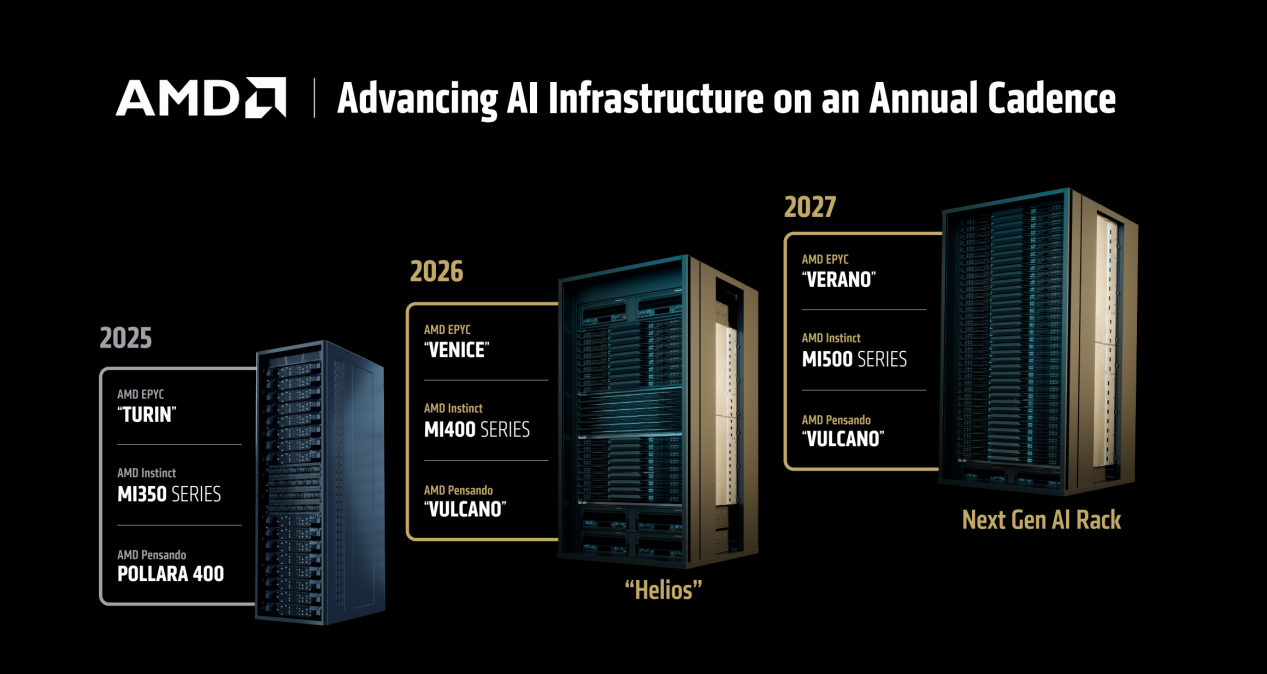
在美國加州圣何塞當地時間6月11日的報道中,我們已經介紹過AMD最新的INSTINCT MI350系列GPU和對應的AI RACK解決方案,同時也簡單提到了2026年和2027年即將登場的兩套AI RACK方案,分別使用了當年對應的新款EPYC處理器以及MI400和MI500 GPU。而在6月12日,AMD 董事會主席兼首席執行官Lisa Su 博士在ADVANCING AI 2025大會的KEYNOTE演講中進一步透露了下一代EPYC處理器“Venice”、MI400 GPU和代號“Vulcano”的Pensando超級網卡的細節。
首先是代號Venice的第六代EPYC,它采用Zen6架構,使用2nm制程,最高可擁有256核心,CPU與GPU之間的連接帶寬提升一倍,同時性能相對上代可提升70%,內存帶寬也達到了1.6TB/s,2026年內登場。雖然信息還不夠多,但由此可以推斷,明年Zen6架構的消費級產品也會出現,性能提升幅度也會非常可觀。明年代號Helios的新一代AI Rack方案就會配備Venice處理器,提供更加強大的AI性能和擴展性。

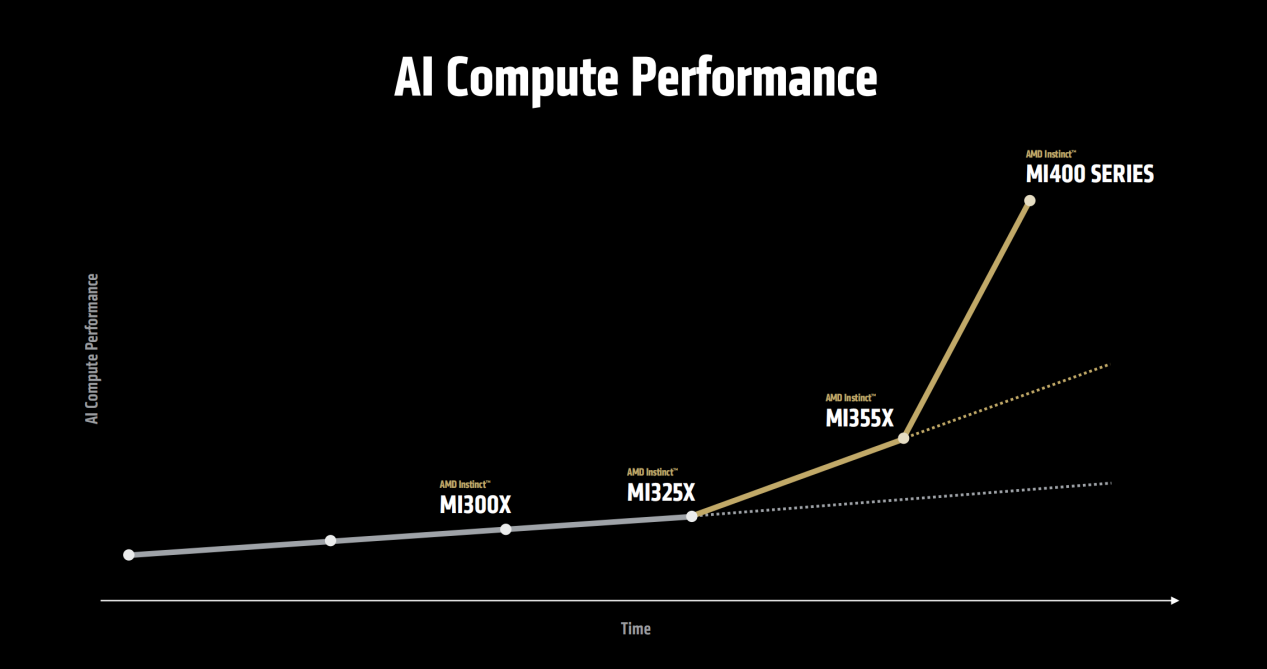
MI400 GPU昨天的文章里我們已經介紹過了,它在MI350系列的基礎上進一步大幅提升性能,FP4/FP8性能高達40PF/20PF,搭載HBM4顯存,最高可達432GB,顯存帶寬可達19.6TB/s,擴展帶寬也幾乎翻倍,達到了300GB/s。
同時,AMD還明確表示,搭載MI400的AI Rack方案相對MI355X最高可帶來10倍的性能提升,這可以說是相當炸裂的升級幅度了。

接下來是AI Rack方案里必不可少的“超級網卡”,目前MI350系列的AI Rack方案里搭載的是剛發布的POLLARA 400,數據帶寬可達400Gbps,也就是40萬兆網卡。而明年推出的Vulcano,制程升級到3nm,將會把數據帶寬升級到800Gbps,變成80萬兆網卡,讓GPU的Scale Out帶寬最多升級到原先的8倍,這也是為什么下一代Helios AI Rack整體性能可以提升那么多的重要原因之一。
至于2027年即將登場的搭載“VERANO”處理器與MI500 GPU的AI Rack,目前代號還沒有確定,AMD也沒有更多的技術參數透露,唯一可確定的是它也會使用800Gbps帶寬的Vulcano超級網卡。

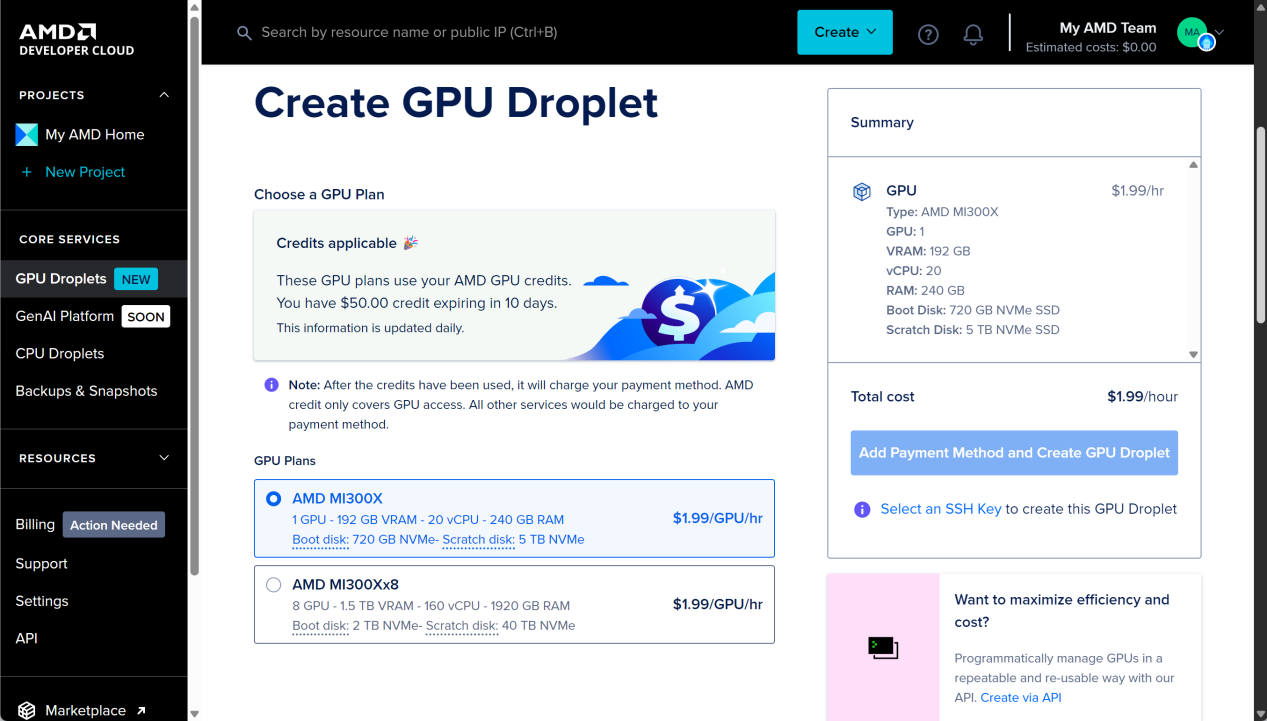
簡單總結一下ADVANCING AI 2025發布的重點產品與項目上線時間。MI350目前正在加緊生產,對應的最終產品今年第三季度上市;ROCm 7則將在8月上線;AMD Developer Cloud服務目前已經上線,大家都可以去申請,前1500名申請者可以獲得10天內25小時的試用權限,之后收費標準為每GPU每小時1.99美元,目前可選MI300X GPU方案(單GPU或8 GPU)。這個收費標準還是比較實惠的,對于研究與學習AI的開發者來說非常實用。
接下來讓我們一起逛逛ADVANCING AI 2025大會DEMO展示區吧。
DEMO區最搶眼的當然就是MI350 GPU和對應的OAM模塊、UBB8模塊實物了。可以看到,MI350 GPU中間是巨大的XCD與IOD堆疊的Die,周圍是8顆HBM3E顯存,整顆芯片碩大無比。而OAM模塊則加上了OAM基板和周邊電氣元件,以便與UBB基板連接。

而完整的UBB8模塊則可以看到基板上搭載了8顆MI350系列GPU。從官方白皮書我們可以知道,1000W TBP的MI350X提供風冷版UBB模塊,而1400W的MI355X則只有液冷UBB模塊,但液冷版更薄,因此可以做到單個Rack里放入更多的UBB模塊。
現場我們也見到了POLLARA 400超級網卡的實物,看起來非常小巧,但卻擁有400Gbps高帶寬。由于性能強悍,所以我們也可以看到它配備了碩大的散熱器。
 本次大會DEMO區展出最多的就是基于MI350系列GPU的AI 解決方案了。這臺Supermicro GPU A+服務器就配備了雙EPYC 9005/9004處理器,8個MI350X GPU,支持最多6TB DDR5內存。
本次大會DEMO區展出最多的就是基于MI350系列GPU的AI 解決方案了。這臺Supermicro GPU A+服務器就配備了雙EPYC 9005/9004處理器,8個MI350X GPU,支持最多6TB DDR5內存。

來自技嘉的G4L3-ZX1-LAX2,是使用MI355X GPU的液冷版AI服務器。它可以最多支持12塊Pollara 400超級網卡。

來自MiTAC的MI355X Rack水冷解決方案。可以看到Rack里安裝了多個不同的UBB模塊。

來自和碩的方案,可以看到里面除了MI355X AI GPU服務器模塊之外,還有存儲模塊、AI加速服務器模塊等等。
來自華擎的4U/8U方案,都是配備MI355X GPU的型號。
來自Cisco的方案,配備MI350 GPU和MI210 GPU。
然后是一些AI應用方面的展示DEMO,在之前ADVANCING AI 2024上也見過,只不過現在都迭代到了新的版本,效率更高、功能更加強大。
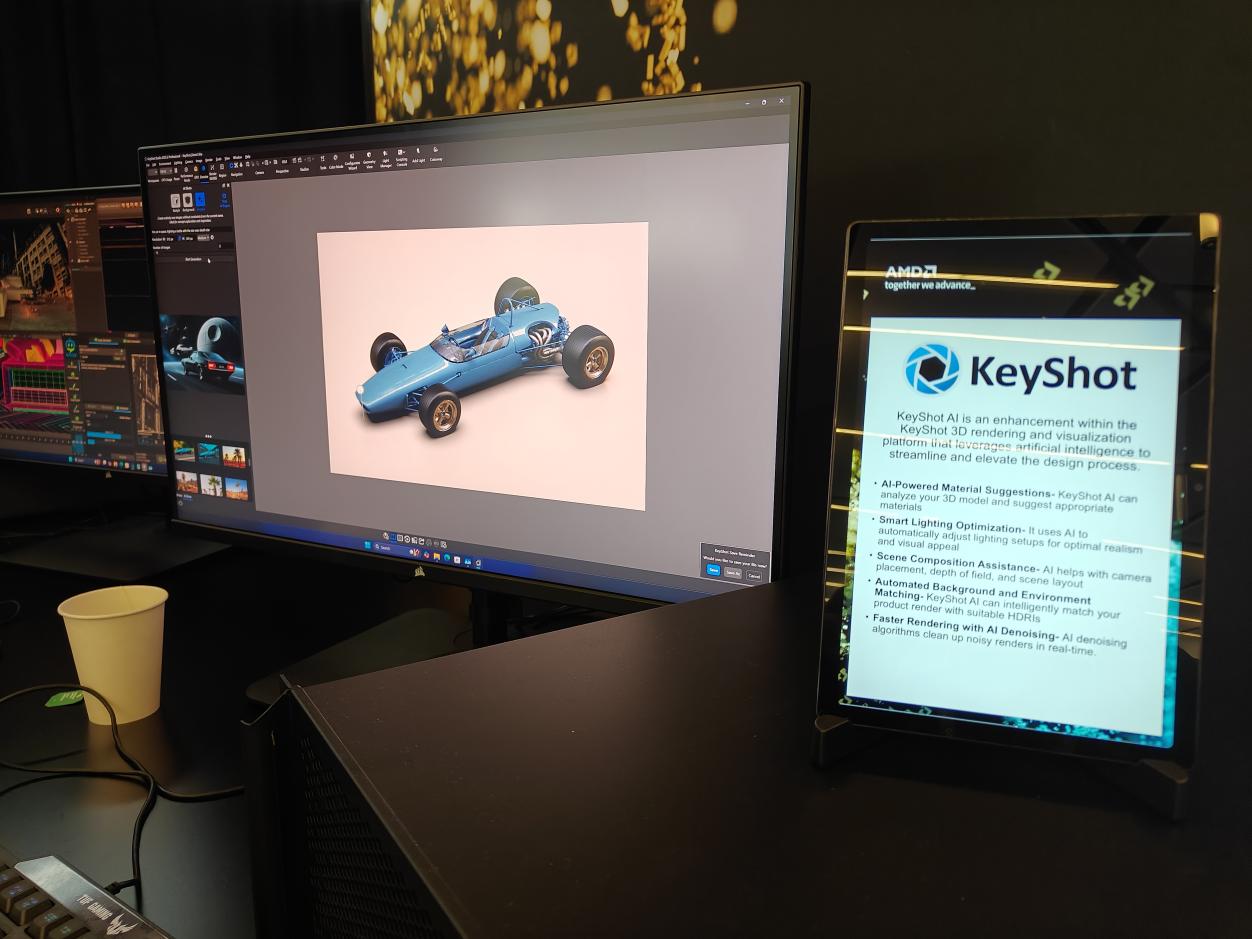
KeyShot目前的AI功能相當強大,它支持AI分析3D模型推薦合適的材質;使用AI自動調整照明設置;智能設置相機位置、景深和場景布局;自動場景匹配和AI降噪。
微軟Copilot的Click to do可以通過AI將操作與屏幕內容聯系起來,它現在已經可以完美支持Ryzen AI NPU了,例如AMD Ryzen AI 300系列移動處理器,就能很好地發揮它的功能。

大名鼎鼎的AMUSE目前也可以通過Ryzen AI NPU實現SD3的AI出圖了。
DaVinci Resolve的AI功能基于DirectML API,可以在AMD平臺上充分發揮性能。
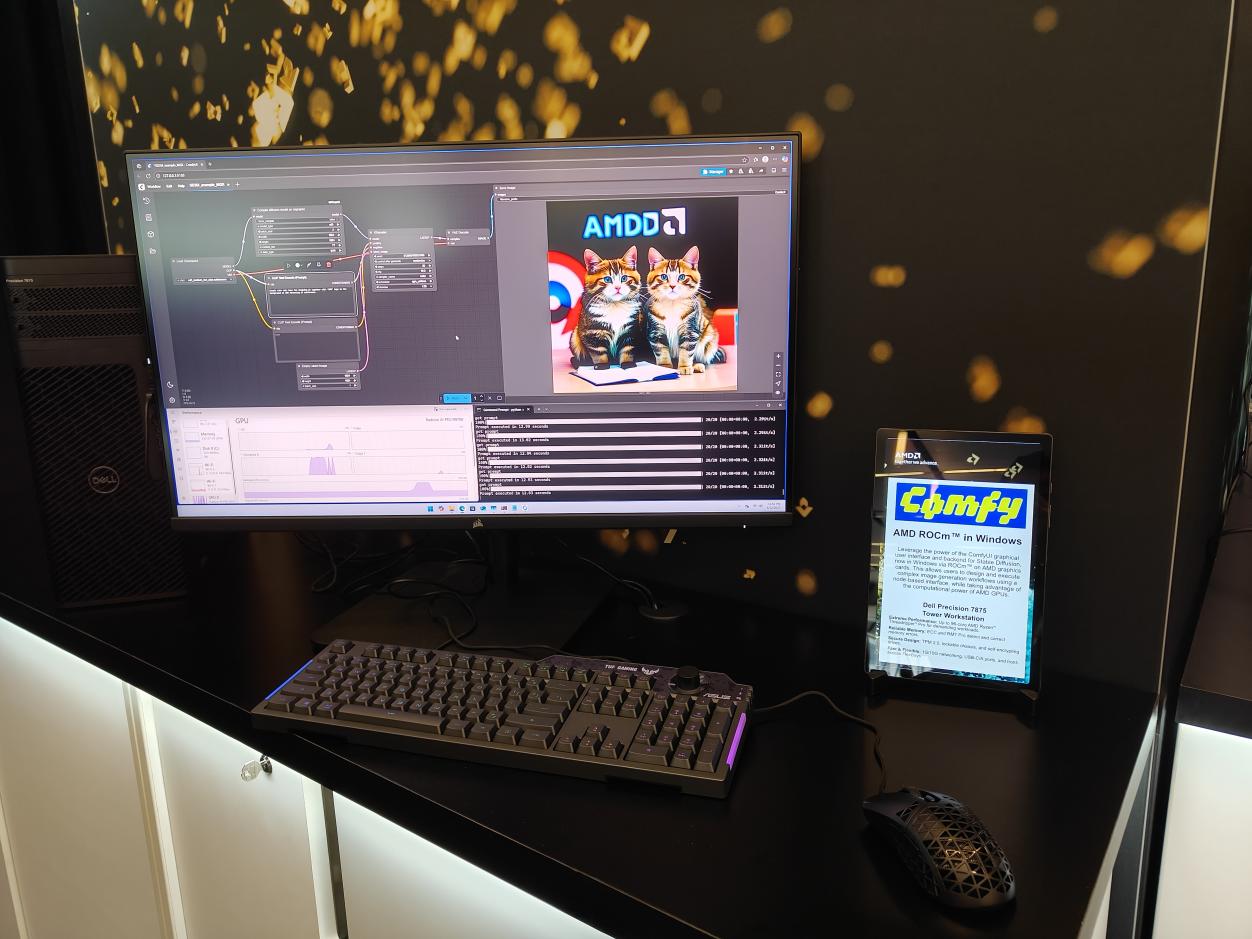
搭載Radeon AI PRO R9700和線程撕裂者處理器的平臺現場展示通過ROCm in Windows和Comfy UI實現AI出圖。實際上,目前的RX 9000消費級顯卡也可以支持ROCm in Windows了,對于普通用戶來說也不失為一個高性價比的AI方案。
諸如GAIA、Blender、Belt、STYRK AI等工具目前也能支持Ryzen AI的NPU和iGPU,對于移動用戶來說,銳龍AI本的實用性也越來越高。

通過AMD顯卡實現的AI渲染技術目前正在研發中。
AMUSE通過AMD GPU實現對實時采集的視頻添加AI濾鏡,生成不同風格的視頻畫面。

OK,其實DEMO區展示的內容還不止這些,可以看到每一年的ADVANCING AI大會都會給我們帶來新的驚喜。例如在去年的ADVANCING AI大會上,一些AI應用還并不能完全利用Ryzen AI NPU,而本次大會展示的新版本就已經對Ryzen AI NPU提供了完美支持。考慮到AMD對開發者的支持力度越來越大,不但有各種競賽和激勵制度,還上線了提供強大GPU服務器的開發者云平臺,我們有理由相信未來基于AMD平臺的AI應用會越來越出色、越來越好用,同時,這也會讓AMD在AI領域獲得更多的支持與份額。
Copyright 1997-2022?電腦報官網?All Rights Reserved















 渝公網安備 50010302003670號
渝公網安備 50010302003670號